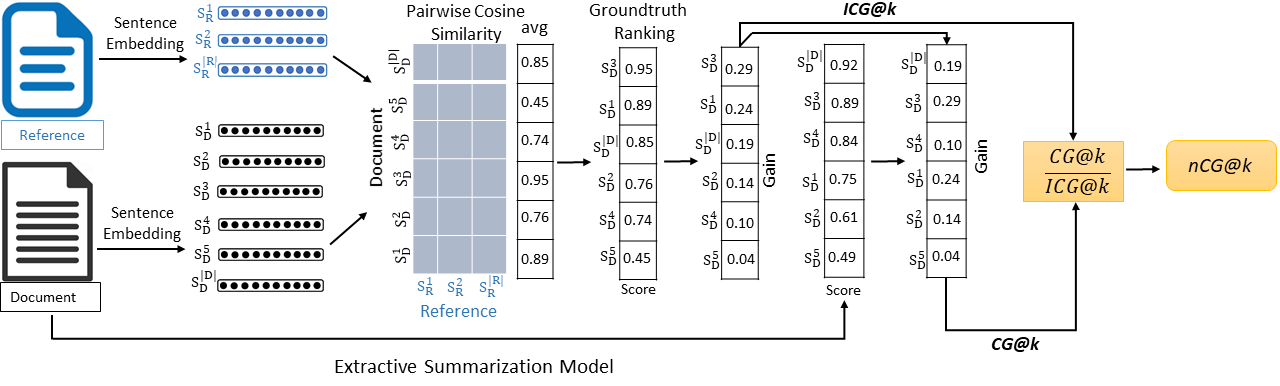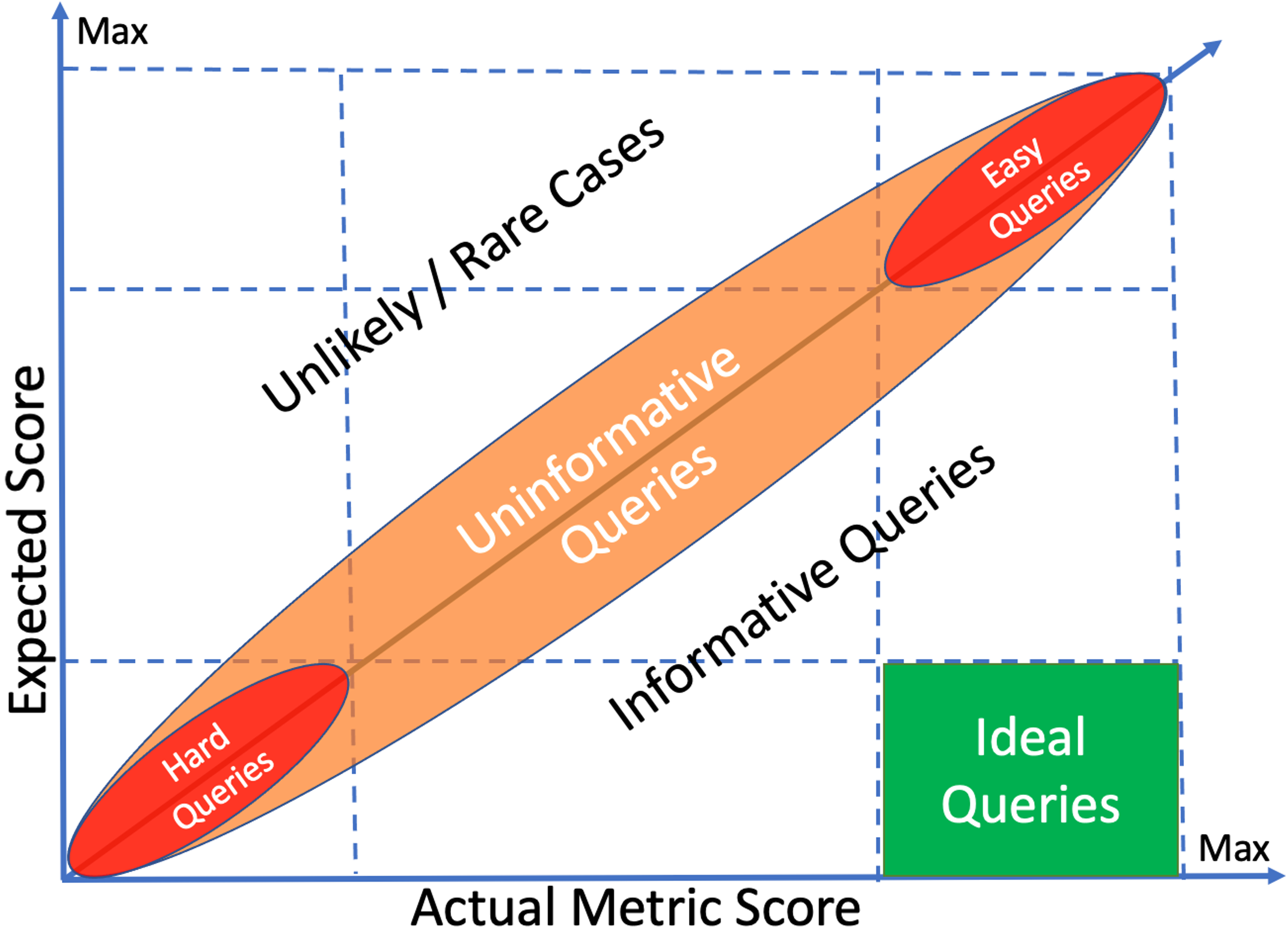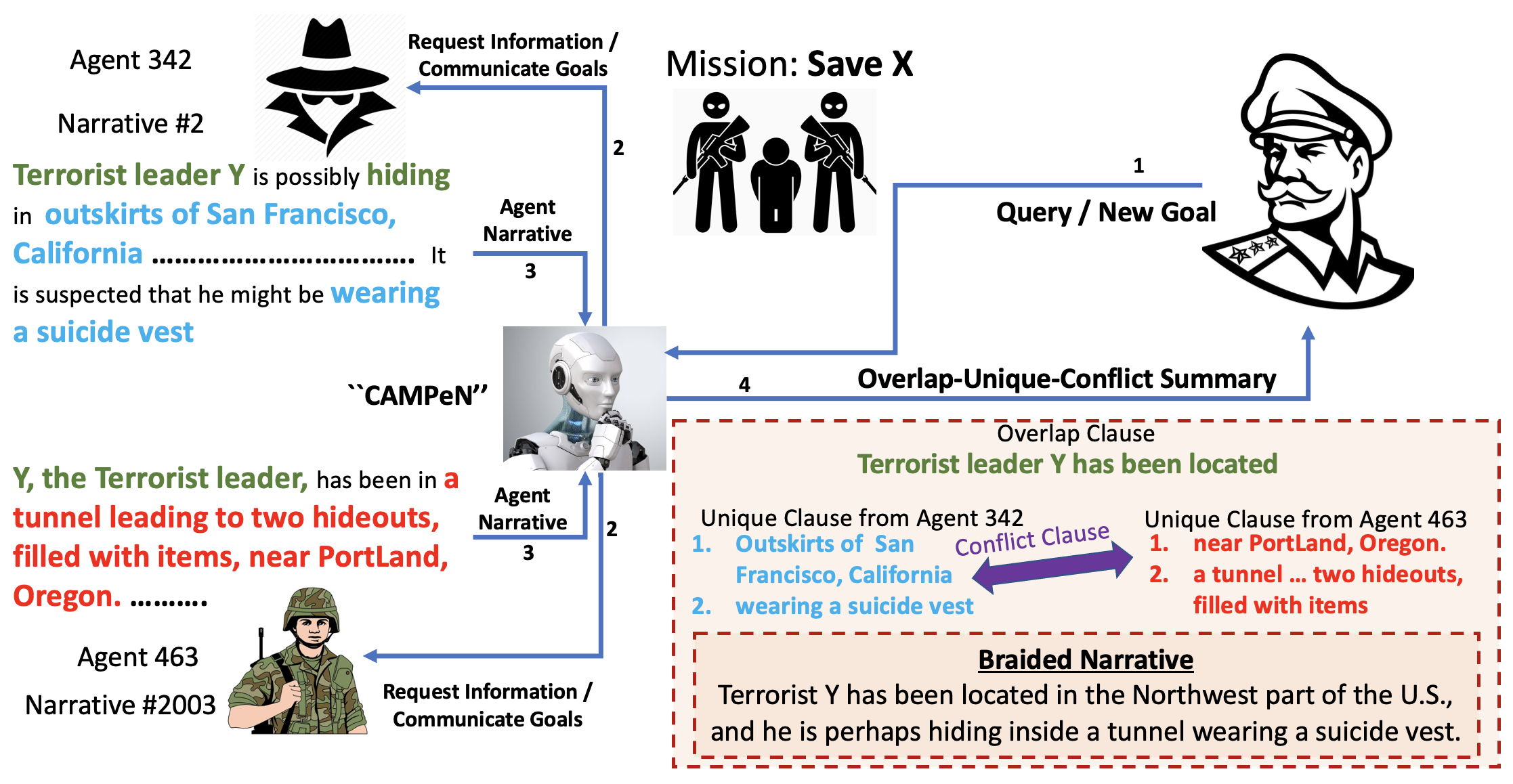
Overview of Project CAMPeN
Multi-Perspective Narratives (MPNs) are ubiquitous and very useful for verifying information from different alternative narratives, and thus, MPNs facilitate more informed decisions by providing a concise overall picture of the current situation. Despite great progress in the area of natural language processing (NLP), computers are still far from being able to analyze multi-perspective narratives accurately; addressing this limitation is the focus of this project.
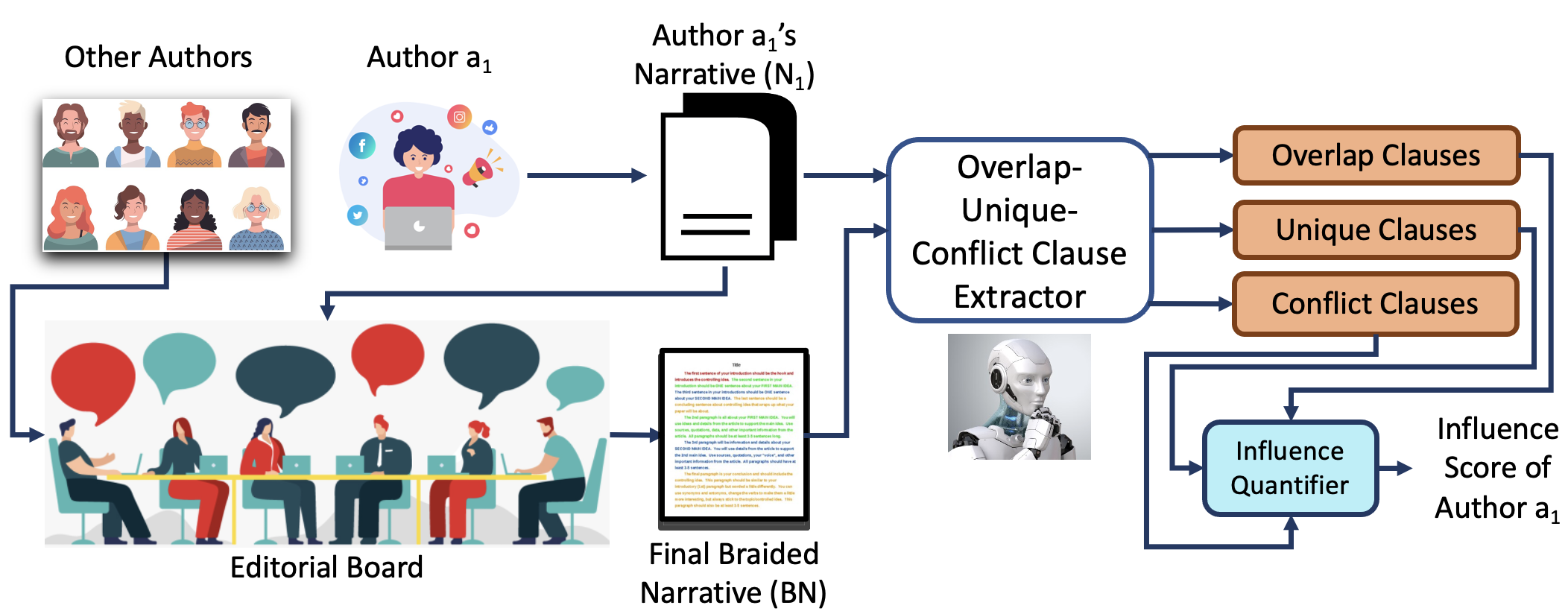
In this ongoing project, we are developing a novel human-AI collaborative framework called CAMPeN (``Collaborative Analytics of Multi-Perspective Narratives’’), where the AI, given multiple alternative narratives as input, first extracts a set of candidate clauses w.r.t. the Overlap-Unique-Conflict criteria, separately, in a zero-shot fashion. Next, the human actively verifies clauses that were labeled with low confidence by the AI. Finally, the machine braids the high-confidence/verified clauses to construct the ultimate Overlap-Unique-Conflict style summary, which will be presented to the user. The major benefits of the proposed framework are two-fold: 1) it enables domain experts in fields other than machine learning/NLP (e.g., a military general) to quickly dig out/verify interesting hypotheses from multiple alternative narratives/descriptions without worrying about the underlying computational techniques and thus, democratizes AI, and 2) it can quickly verify facts and claims about real-world events by analyzing alternative narratives and braid them into a single narrative with a higher degree of Information Assurance.
This project adopts both zero-shot and reinforcement learning approaches for extracting overlapping, unique, and conflicting information from alternative narratives that can be trained in a self-supervised fashion without requiring a large collection of training data; therefore, the proposed framework needs minimal human supervision in comparison to the existing Multi-Document Summarization techniques. Additionally, the project borrows intuitions and insights from the classical set theory and applies the properties of set operators to develop novel reward/loss functions to enable effective training of reinforcement learning-based extraction networks.
Objectives of Project CAMPeN
The proposed work includes the following objectives.
- Design and develop a novel human-AI collaborative framework that can braid the Overlapping, Unique, and Conflicting information from a pair of alternative narratives into a single coherent summary.
- Conduct research on how to extract overlapping information from a pair of alternative narratives and paraphrase the overlap.
- Given a pair of alternative narratives as inputs, conduct research on how to extract unique information present exclusively in each input narrative and identify interesting, unique information.
- Conduct research on how to extract conflicting information from a pair of alternative narratives and how to resolve the conflict via effective human-AI collaboration.
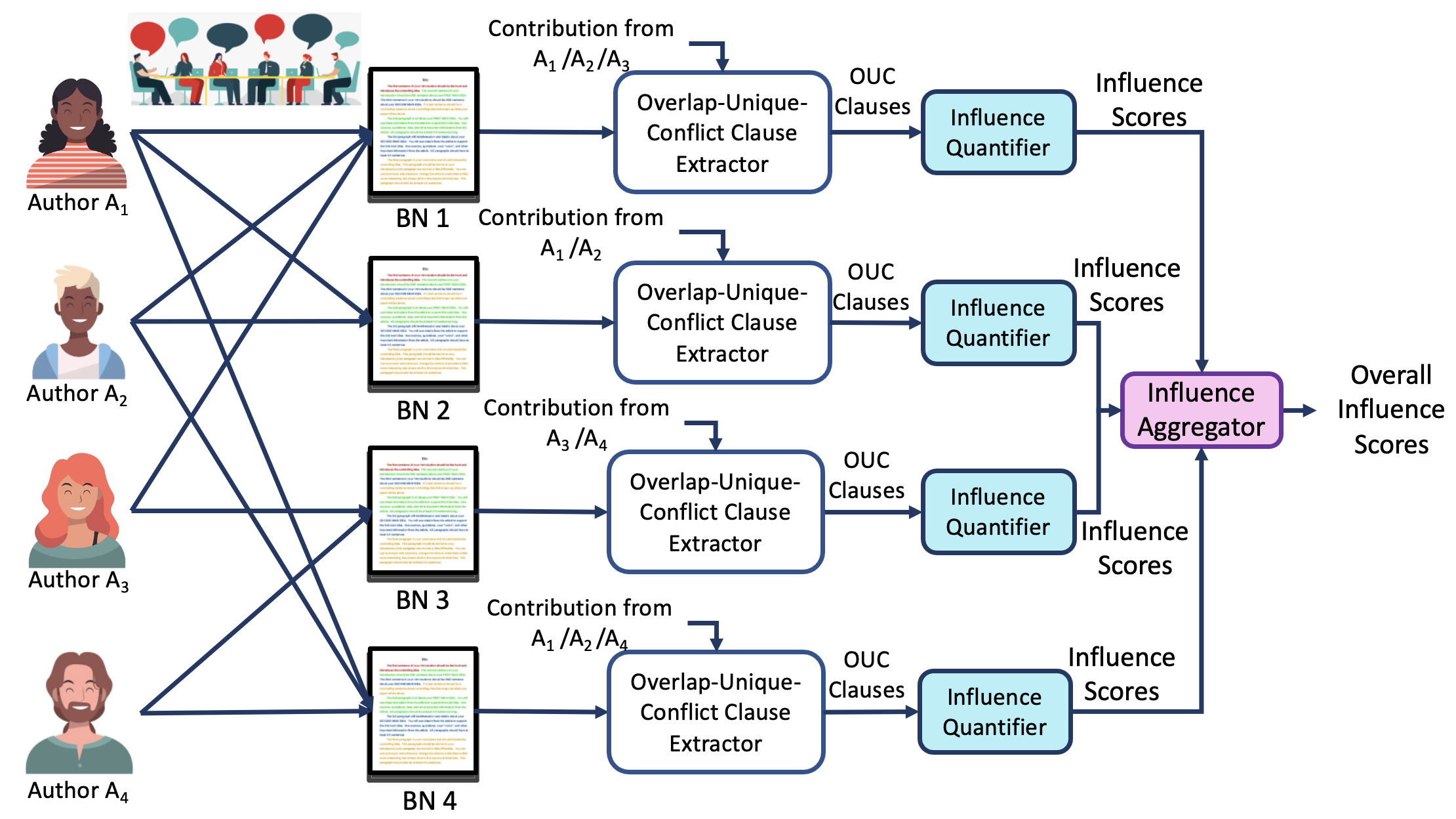
- Design and Develop novel metrics for quantifying Author Influence by applying the proposed Human-AI collaborative framework.
- Conduct a thorough quantitative and qualitative evaluation of the proposed human-AI collaborative framework.
- Determine whether the proposed Human-AI collaborative framework performs similarly or differently in a language other than English.