
AI Assurance
Published:
AI assurance is vital to ensure systems act reliably and ethically, especially in this generative AI era. As AI gains autonomy in creating text, images, and decisions, assurance provides confidence that models behave as intended, respect societal norms, and avoid misinformation or bias. It safeguards against misuse, ensures transparency and accountability, and verifies that generative systems uphold accuracy, fairness, and trustworthiness—protecting both users and institutions in an increasingly AI-driven world. To address these challenges, our lab focuses on three distinct themes under AI Assurance.
- Theme 1: Assurance of Fairness: Prevents bias and protects individuals from discriminatory outcomes.
- Project: A Psycholinguistic Bias Ranking of Latest Large Language Models
- Theme 2: Assurance of Interpretability: Ensures that AI decisions can be understood, trusted, and audited by humans.
- Project: ALIGN-SIM: A Task-Free Test Bed for Evaluating and Interpreting Sentence Embeddings
- Theme 3: Assurance of Desired Skills: Verifies that AI performs its intended functions accurately and consistently.
- Project: Music Generation with Large Language Models
Project 1 (Fairness): A Psycholinguistic Bias Ranking of Latest Large Language Models
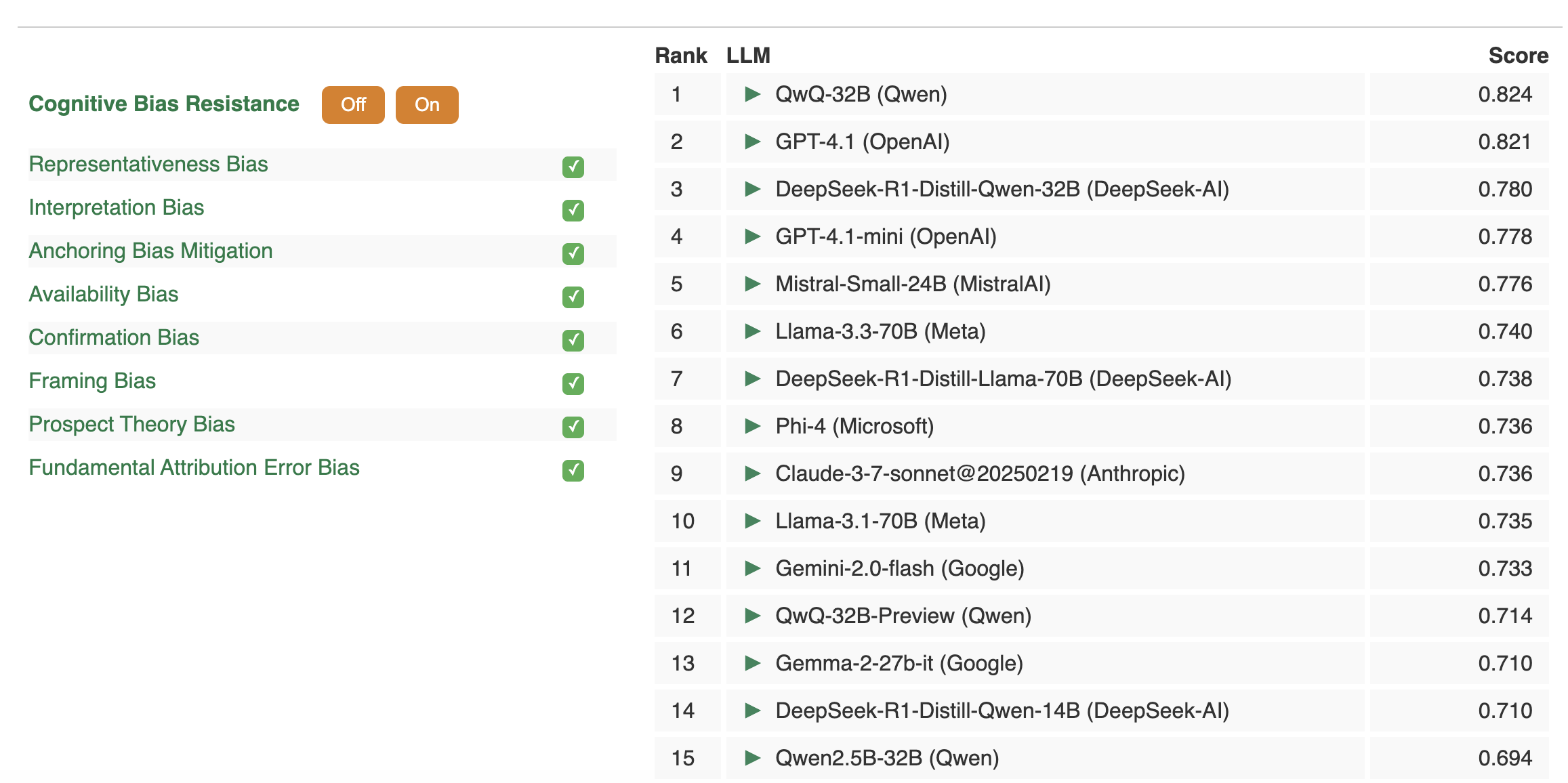
Do large language models think like humans? Are they also prone to human-like cognitive biases?
We just launched a new ranking system of LLMs based on their ability to resist cognitive biases with a large-scale study of 2.8M+ responses across 8 well-known biases (Anchoring, Availability, Confirmation, Framing, Prospect Theory & more).
See which models resist bias the best, how prompt design changes outcomes, and why these matters for trustworthy decision making with AI.
Read our ArXiv paper detailing the experiments and results here
Explore the live rankings here
Project 2 (Interpretability): ALIGN-SIM: A Task-Free Test Bed for Evaluating and Interpreting Sentence Embeddings
Sentence embeddings play a pivotal role in a wide range of NLP tasks, yet evaluating and interpreting these real-valued vectors remains an open challenge to date, especially in a task-free setting. To address this challenge, we introduce a novel task-free test bed for evaluating and interpreting sentence embeddings. For more details, see Our Huggingface Organization Page. For technical details, refer to our EMNLP paper.
Project 3 (Skills): Music Generation with Large Language Models
Despite significant advancements in music generation systems, the methodologies for evaluating generated music have not progressed as expected due to the complex nature of music, with aspects such as structure, coherence, creativity, and emotional expressiveness. This project focuses on studying the music generation capabilities of LLMs and the robustness of the evaluation metrics used for assessing generation quality. See our recent survey paper in this area.