Utility Centric Evaluation
Published:
In this project, our main goal is to investigate how to make NLP/IR evaluation metrics more utility-centric and robust.
Overview of Project “Utility Centric Evaluation”
Previous studies have shown that popular Natural Language Generation (NLG) and Information Retrieval (IR) and evaluation metrics, e.g., nDCG, ROUGE, MAP, are not robust and often do not correlate with the utility perceived by humans. In this project, our main goal is to investigate how to make NLP/IR evaluation metrics more utility-centric.
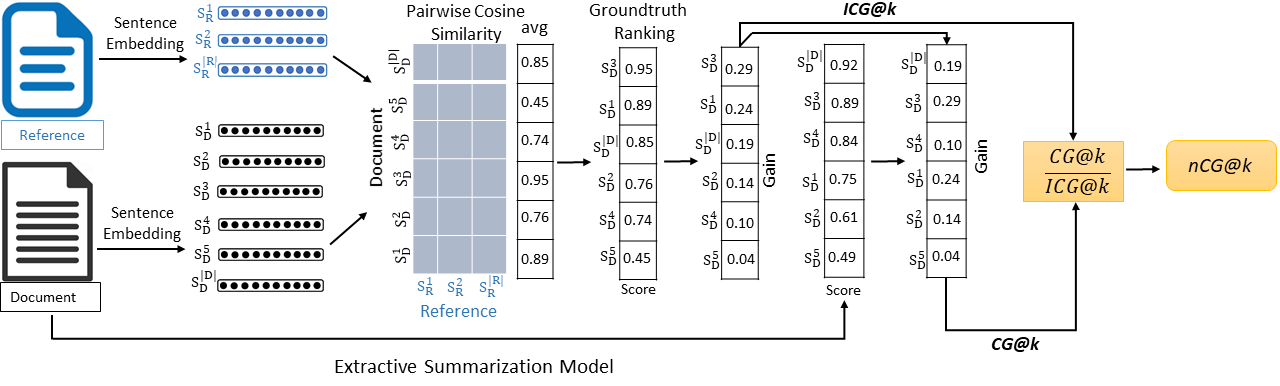
- Utility-Centric Metrics for Evaluating Text Generation Systems: In ACL 2022, we proposed a gain/utility-based automated metric called Sem-nCG, which is both rank and semantic aware, for evaluating extractive summarization tasks and showed that Sem-nCG exhibits a higher correlation with human judgments than the popular ROUGE metric. In the same year (EMNLP 2022), we proposed a new sentence-level utility-based evaluation metric, called SEM-${F_1}$ (Semantic $F_1$), for evaluating the performance of the Overlap summary generation task. Experimental results show that the proposed SEM-$F_1$ metric yields a higher correlation with human judgment and inter-rater agreement than the traditional ROUGE metric. Very recently, we proposed TELeR, a general taxonomy for benchmarking complex generation tasks using Large Language Models (LLMs). TELeR enables meaningful comparisons across studies, establishing a common standard for prompt design and LLMs' Utility Evaluation; the taxonomy has received great attention from the industry and practitioners.
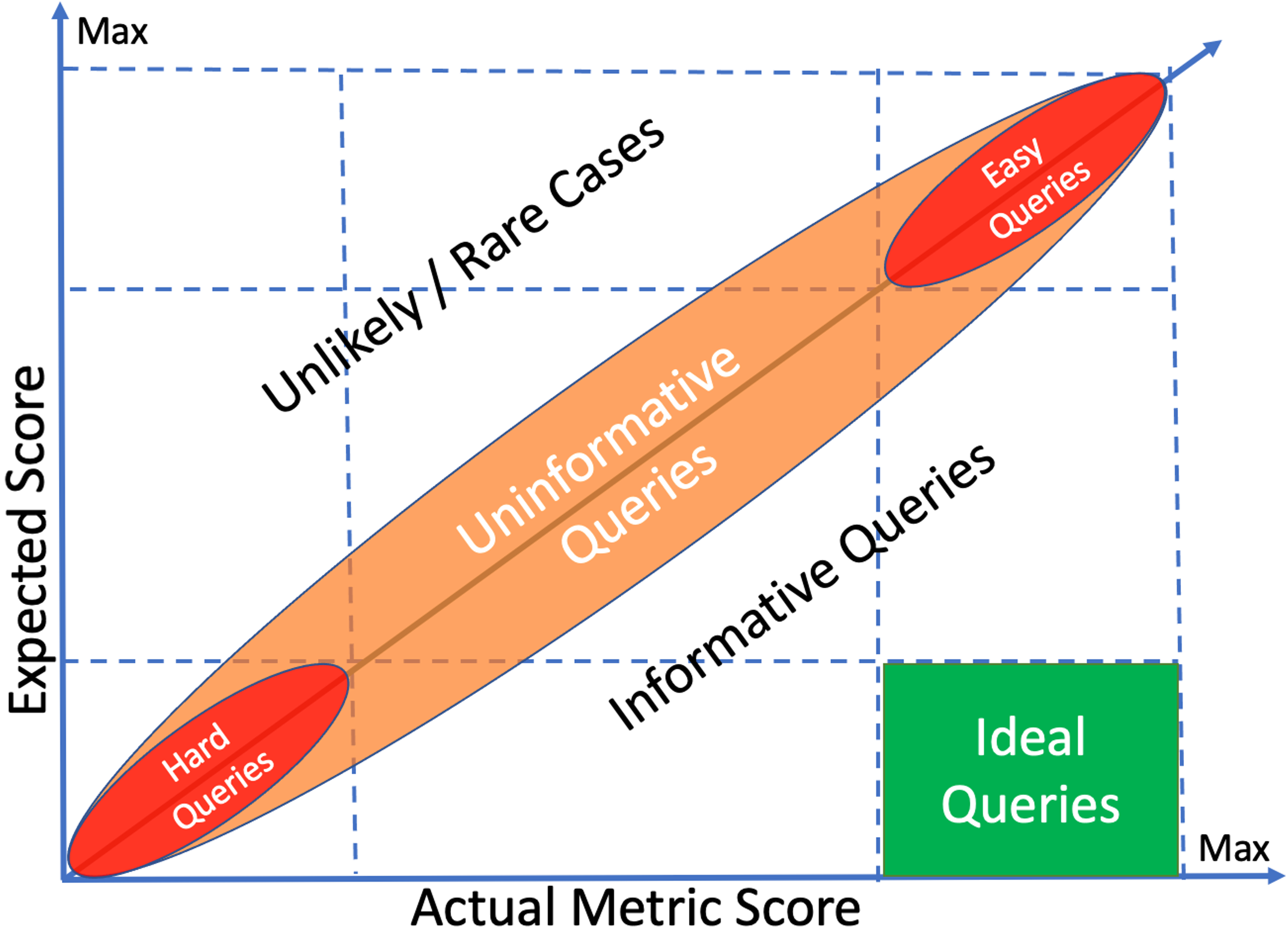
- Utility-Centric Metrics for Evaluating Ranking Systems: We recently proposed a novel framework for ranking evaluation with expected-utility normalization, where the expected utility is estimated from a randomized ranking of the corresponding documents present in the evaluation set. Our proposed metric demonstrates an average of 21% increase in Discriminatory Power and a 28% increase in consistency. In a similar line of research, I previously performed a detailed evaluation of learning-to-rank methods for both Web search and E-Commerce search by exploiting multiple utility-based signals in addition to click rates, i.e., add-to-cart ratios, order rates, and revenue, results of which were published in CIKM 2022 (Best Poster Nomination) and SIGIR 2017 conference proceedings. The E-Commerce search study yielded multiple interesting insights and results that received significant attention from the search industry, including Walmart, Flipkart, @Unbxd, etc.