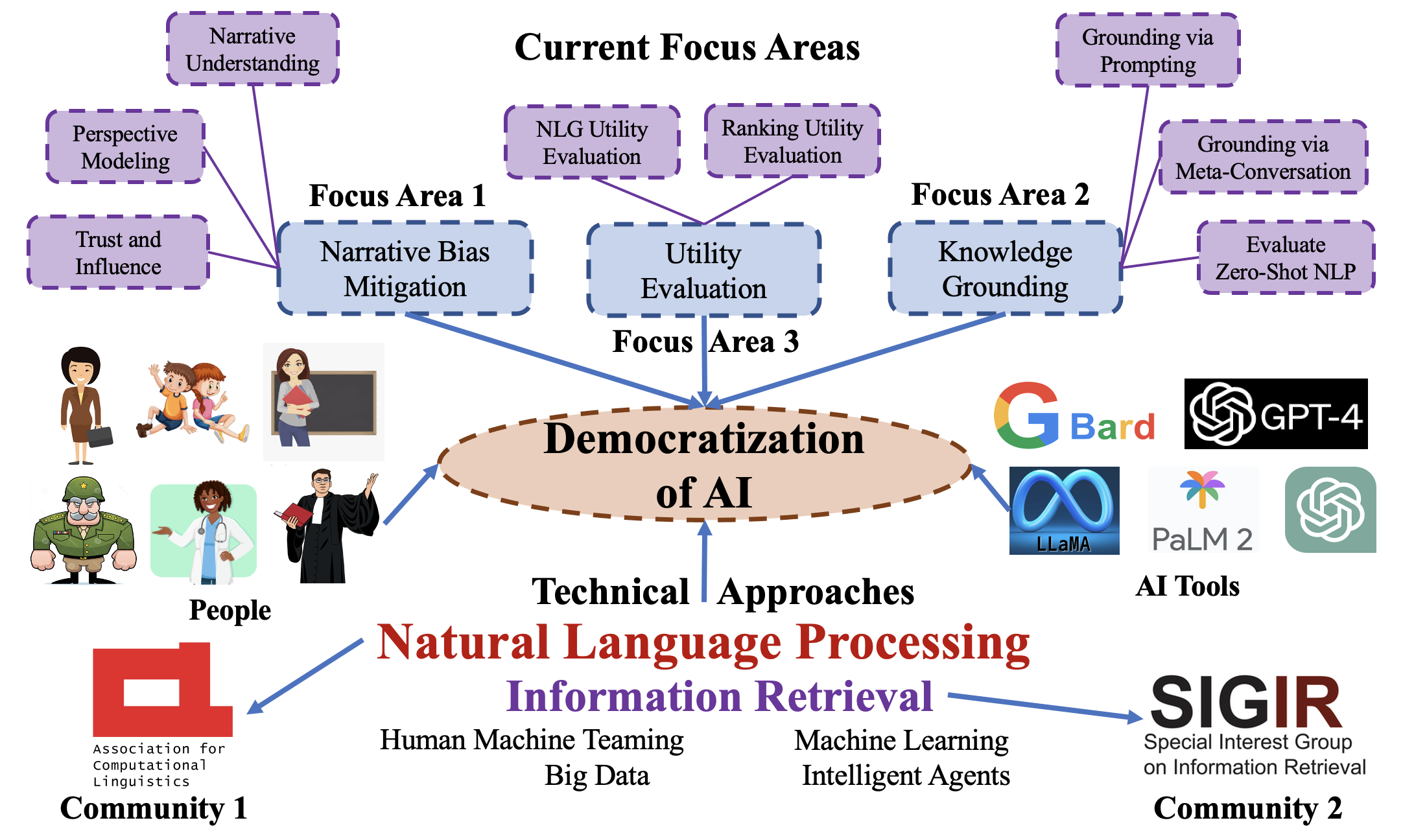
My long-term research goal is centered around the following question: "How can we make AI/Data Science more accessible and useful to the end users in order to democratize AI to a wider audience?" As a researcher, I find myself at the intersection of Natural Language Processing (NLP) and Information Retrieval (IR), with a broad interest in the general area of Artificial Intelligence and Data Science (see Figure below).
Even though Artificial Intelligence (AI) has existed for a long time, its broad accessibility is a recent development, thanks to ChatGPT for its human-like interactions. While such broad accessibility provides a great opportunity to democratize AI across general people, it comes with several key risks and challenges, including but not limited to, lack of Knowledge Grounding/Contextual Understanding, an abundance of Biased Contents/Narratives, and lack of Utility-Centric Evaluation of AI systems. As such, my current research focuses on these three specific challenges (see Figure below), i.e., 1) Narrative Debiasing, 2) Knowledge Grounding and 3) Utility-Centric Evaluation of NLP/IR Systems. Additionally, I plan to grow my research program into the following emerging areas related to democratization of AI: Energy Efficient NLP and Conversational Software Testing.
The objective of this research is to design and develop a novel human-AI collaborative framework that can braid the Overlapping, Unique, and Conflicting information from a pair of alternative narratives into a single coherent summary.
This is an ongoing project in my lab, where we are developing a “Meta-Conversation Framework” to create dialog-based interactive laboratory experiences for middle school science students and teachers in the context of simulation-based science experiments.
This is an ongoing project where we develop conversational AI techniques by prompting Large Language Models (LLMs) to build a natural language interface between humans and the AutoML tools (e.g., Scikit-Learn), which, in turn, can facilitate acquiring new predictive skills via self-directed learning. To achieve this, we recently introduced a new prompting taxonomy called TeLER to design diverse prompts that can unleash the full potential of LLMs with proper knowledge grounding.
This ongoing project aims to develop a novel metric to quantify an author’s influence in the narrative braiding process by comparing the final braided narrative against the individual author’s contribution in terms of the Overlap-Unique-Conflict clauses extracted by the CAMPeN framework.