
Empirical Analysis of Impact of Query-Specific Customization of nDCG: A Case-Study with Learning-to-Rank Methods
Published in ACM CIKM, 2020
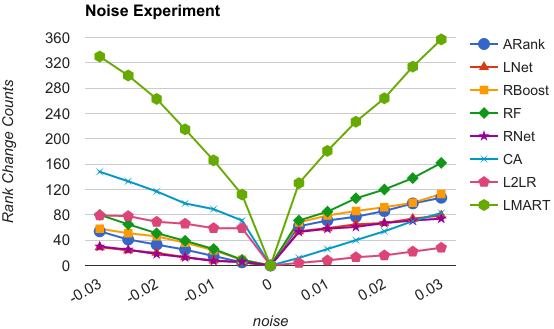
In most existing works, nDCG is computed for a fixed cutoff $k$, i.e., $nDCG@k$ and some fixed discounting coefficient. Such a conventional query-independent way to compute nDCG does not accurately reflect the utility of search results perceived by an individual user and is thus non-optimal. In this paper, we conduct a case study of the impact of using query-specific nDCG on the choice of the optimal Learning-to-Rank (LETOR) methods, particularly to see whether using a query-specific nDCG would lead to a different conclusion about the relative performance of multiple LETOR methods than using the conventional query-independent nDCG would otherwise. Our initial results show that the relative ranking of LETOR methods using query-specific nDCG can be dramatically different from those using the query-independent nDCG at the individual query level, suggesting that query-specific nDCG may be useful in order to obtain more reliable conclusions in retrieval experiments.