
SOFSAT: Towards a Setlike Operator based Framework for Semantic Analysis of Text.
Published in ACM SIGKDD Explorations [Position Paper] , 2018
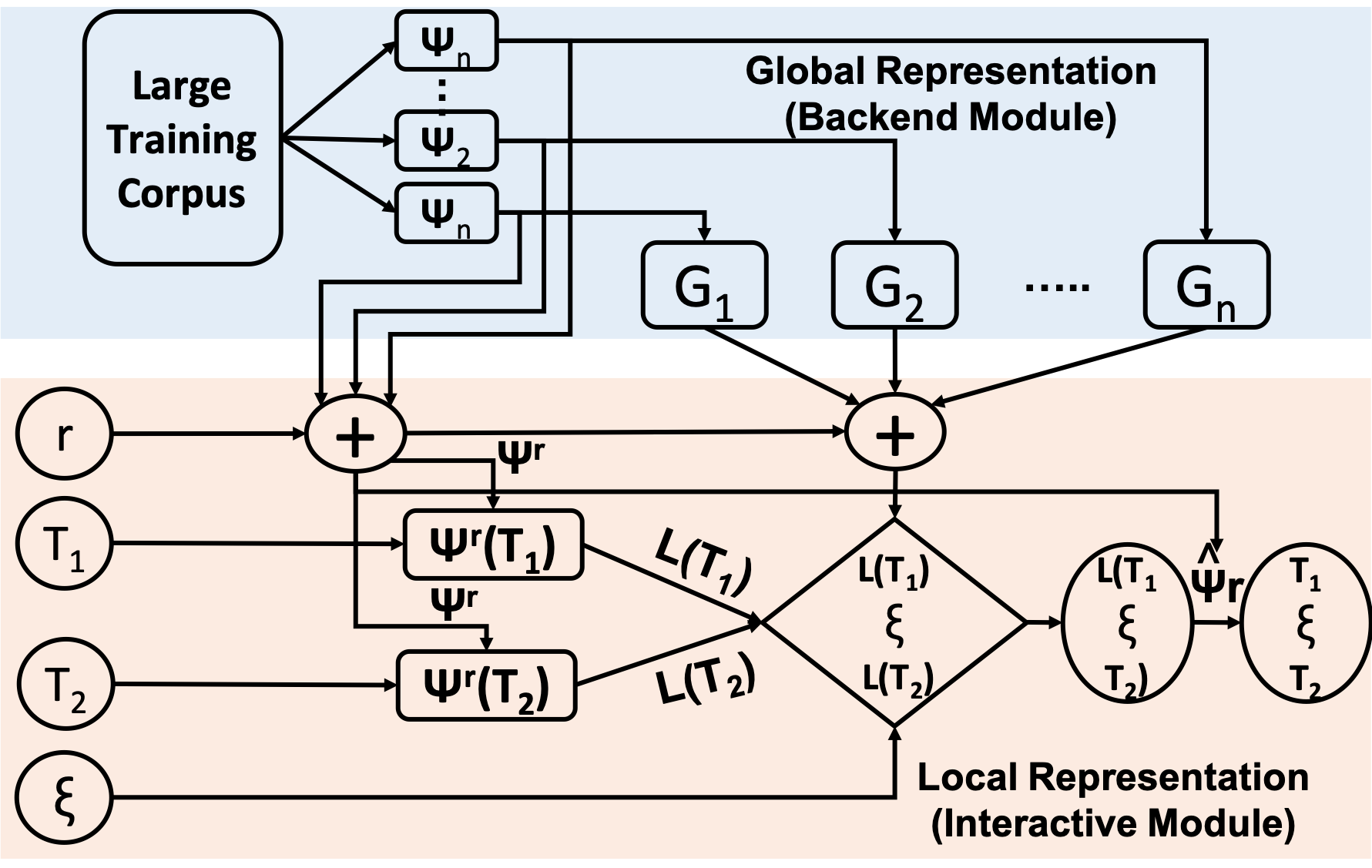
As data reported by humans about our world, text data play a very important role in all data mining applications, yet how to develop a general text analysis system to support all text mining applications is a difficult challenge. In this position paper, we introduce SOFSAT, a new framework that can support set-like operators for semantic analysis of natural text data with variable text representations. It includes three basic set-like operators-TextIntersect, Tex-tUnion, and TextDifference-that are analogous to the corresponding set operators intersection, union, and difference, respectively, which can be applied to any representation of text data, and different representations can be combined via transformation functions that map text to and from any representation. Just as the set operators can be flexibly combined iteratively to construct arbitrary subsets or supersets based on some given sets, we show that the corresponding text analysis operators can also be combined flexibly to support a wide range of analysis tasks that may require different workflows, thus enabling an application developer to "program" a text mining application by using SOFSAT as an application programming language for text analysis. We discuss instantiations and implementation strategies of the framework with some specific examples, present ideas about how the framework can be implemented by exploiting/extending existing techniques, and provide a roadmap for future research in this new direction.